

一、线性表
1、线性表的顺序存储
1 | const LIST_INIT_SIZE=100;//表初始分配空间 |
1、线性表的初始化(创建一个空的线性表)
1 | Status InitList_Sq(SqList &L){ |
注意:ElemType为数据类型,比如可以为int类型。
1 | L.elem=(int *)malloc(LIST_INIT_SIZE*sizeof(int)); |
线性表有两种结构:
- 物理结构:也就是存储结构
- 逻辑结构:也就是你定义的结构,可以为顺序结构,线性结构。
顺序存储结构:它的逻辑结构与物理结构是相同的,也就是用连续的存储单元。只需要定义一组连续的存储单元就行,然后把这个连续的存储单元的基地址,用某个变量来标注它。就比如:ElemType *elem,然后每个元素的地址系统都可以自己计算出来的。顺序存储结构,基地址知道了,就可以随机的存取。你取任何一个元素访问的时间是相同的。
在顺序存储结构中,定义的方式不仅仅是一个数组。此处定义采用的是指针的方法。因为基地址可以用一个指针来记住它。
2、删除线性表中的第i个元素
1 | Status ListDelete_Sq(SqList &L,int i,ElemType &e){ |
注:第i个元素的下标是i-1,因为数组是从0开始的。
3、顺序表的应用
例1、设A=(a1,a2,a3,…am),B=(b1,b2,b3,…bn)为两个线性表,试写出比较A,B大小的算法。
比较原则:首先去掉A,B两个集合的最大前缀子集之后,如果A,B为空,则A=B;如果A空B不空,A<B;如果B空A不空,则A>B;如果A和B均不空,则首元素大者为大。
分析:A,B看成是顺序表,从前往后一次比较他们两个相同下标的元素。
1
2
3
4
5
6
7
8
9
10
11
12int compare(SqList A,SqList B){
//若A<B,返回-1,A=B返回0,A>B返回1
int j=0;
while(i<A.length&&j<B.length){
if(A.elem[j]<B.elem[j])return -1;
else if(A.elem[j]>B.elem[j])return 1;
else j++;
}
if(A.length==B.length)reutrn 0;
else if(A.length<B.length)return -1;
else return 1;
}
例2、设计一个算法,用尽可能少的辅助空间将顺序表中前m个元素和后n个元素进行整体互换。即将线性表,也就是O(m+n)空间复杂度
(a1,a2,…am,b1,b2,…,bn)—–>(b1,b2,….,bn,a1,a2,…,am)
如果两两交换的话,要考虑m,n的大小。
参考算法1:取一个临时空间,将b1放入临时空间,
把a1到am看成一个整体搬迁后移一个位置,如此b2,b3,直到bn。
1
2
3
4
5
6
7
8
9
10void exchange(SqList &L,int m,int n){
//线性表分成两个部分后,两部分倒置
for(int i=0;i<n;i++){//第一个for把b1到bn一个个放到临时存储空间w
int w=L.Elem[i+m];//i+m=0+m也即是b1的下标
for(j=m;j>=1;j--)
L.Elem[i+j]=L.Elem[i+j-1];//然后把a1到am元素整体往后移动一个位置。
L.Elem[i]=w;
}
}
算法特点:牺牲时间节省空间,时间复杂度O(m*n)参考算法2:如果另外申请空间m+n个存储单元,将b,a分别写入,时间复杂度将为m+n,也就是:牺牲空间节省时间。
1
2
3
4
5
6
7
8
9
10
11void exchange(SqList &L,int m,int n){
SqList List;//为m+n长度
//存放b1,b2,...bn
for(int i=0;i<n;i++){
List.Elem[i]=L.Elem[i];
}
//存放a1,a2,am
for(int i=m;i<=L.length-1;i++){
List.Elem[i]=L.Elem[i];
}
}
2、线性链表的表示、实现、操作
顺序表的局限:插入、删除时要移动大量的元素,耗费大量时间。
链式表示:用一组任意的存储单元存储线性表
- 存储单元不要求连续:物理结构不反应逻辑结构
- 不可以随机存取,但插入和删除方便
- 需要两个域:一个表示数据本身;一个表示数据元素间的先后关联。合起来是一个结点。
- S结点中表示关联的部分为指针域,内部存放指针或者链。结点链接成一个链表。
2、线性链表的表示、实现、操作
3、循环链表的定义
1、线性链表(单链表)的定义:
1 | typedef struct LNode{ |
带头结点的单链表:头结点:data里没有数据。比如把表里元素都删除。总不能只剩下一个L吧。头结点的增加仅仅是为了运算的方便。做题的时候,要看清楚是不是带头结点的链表,默认都是带头结点的链表。
2、线性表的基本操作:
1、初始化线性链表
也就是创建一个仅仅有头结点的空表。
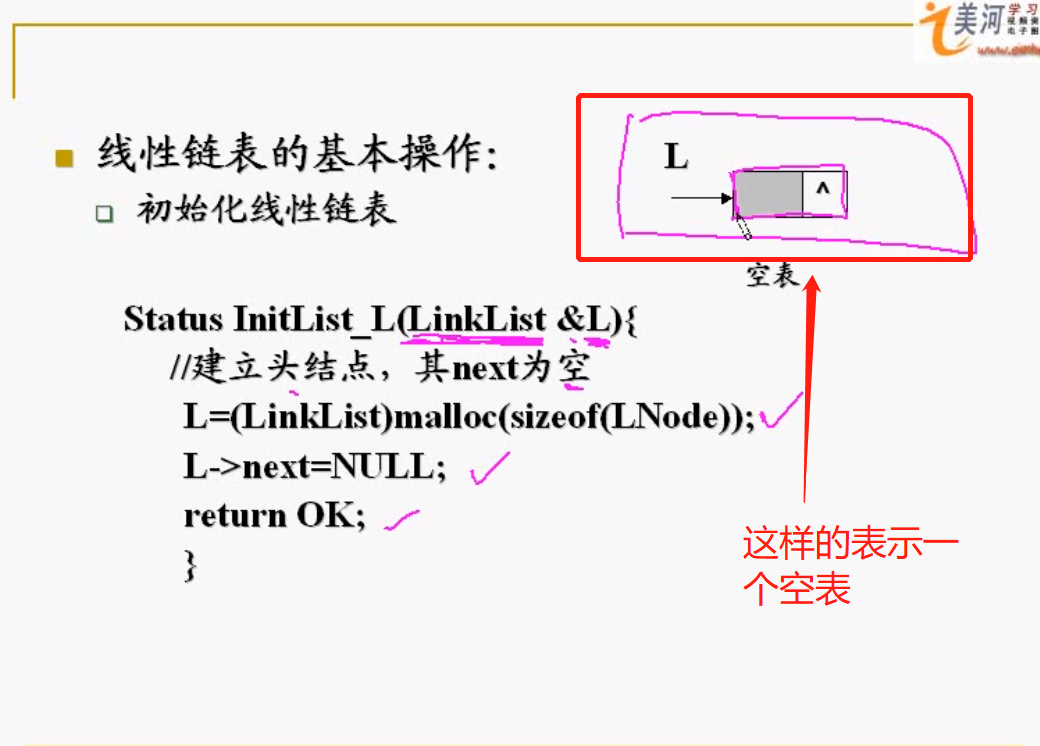
1 | Status InitList_L(LinkList &L){//LinkList,就是刚刚在struct结构体定义的*LinkList |
2、GetElem在单链表中的实现GetElem_L(L,i,&e)
也就是把第i个元素取出来,赋给变量e。
思想:可以使用一个指针p指向第一个元素,然后再用一个计数器flag=1。
或者让指针p指向头结点,可以把计数器flag=0;然后指针不断的往后,计数器flag要不断的+1。
1 | Status GetElem_L(LinkList L,int i,ElemType &e){//使用&e,是因为e的值会发生变化。因为把获取到的值,赋给了e。 |
注:顺序表与单链表在取第i个元素的操作上有什么不同?
顺序表:随机存取
3、插入操作:在第i个结点之前插入一个元素e
1 | Status ListInsert_L(LinkList &L,int i,ElemType e){ |
总结:只要是把值赋给e的操作,都是要用Elem &e,如果只是单纯把e赋给别的,就用Elem e好了。
1 | LNode* LocateElem_L(LinkList L,ElemType e){ |
例题1:将两个有序链表归并为一个新的有序链表。
分析:将Lb中的元素插入到La,使其有序。
pa->data >pb->data:将pb插入到pa的前面。插入过程中,注意临时指针的使用。
声明两个指针,pa指向La的第一个元素,pb指向Lb的第一个元素。
还要额外增加两个辅助变量来记录。比如用p来记录pa前面那个元素。
然后用q来记录pb前面的那个元素。
1 | void mergeList(LinkList &La,LinkList &Lb){ |
4、双向循环链表的定义、操作
5、线性表的典型应用
二、栈和队列
1、栈的抽象数据类型
栈:一个只能在栈顶进行插入和删除的线性表,其特征为FIFO。
栈的表示:
顺序栈:栈的顺序存储
- 优点:处理方便
- 缺点:数组大小固定,容易造成内存资源的浪费。
链栈:栈的动态存储
- 优点:能动态改变链表的长度,有效利用内存资源
- 缺点:处理较为复杂
1.1、顺序栈的表示和实现
1 |
|
1 | //初始化栈 |
1 | //压栈 |
1 | //出栈 |
注:top的操作顺序和值的变化
压栈:value->top;top++;//首先是把值赋给top后,然后top再++,指向当前压栈元素的下一个
弹栈:top–;top->value;//首先是top先–,指向栈顶元素,然后再取值。
1.2、链栈的结构和表示
1 | //定义栈结构 |
1 | //入栈push |
1 | //出栈:相当于把单链表的表头元素给删除掉 |
2、队列
1 | //初始化空队列Q |
2.1、顺序队列
1 |
|
2.2、循环队列
1 | 初始:Q.front=Q.rear=0; |
队列初始化
1
2
3void InitQueue(&Q){
Q.rear=Q.front=0;//初始化队首、队尾指针
}判队空
1
2
3
4bool isEmpty(Q){
if(Q.rear==Q.front)return true;
else return false;
}入队
1
2
3
4
5
6
7bool EnQueue(SqQueue &Q,ElemType x){
if((Q.rear+1)%MaxSize==Q.front)return false;//队满
Q.data[Q.rear]=x;
//入队从队尾
Q.rear=(Q.rear+1)%MaxSize;//队尾指针加1
return true;
}出队
1
2
3
4
5
6
7bool DeQueue(SqQueue &Q,ElemType &x){
if(Q.rear==Q.front)return false;//出队之前,先判断队是否为空
x=Q.data[Q.front];
//出队从队头开始
Q.front=(Q.front+1)%MaxSize;//队头指针加1取模
return true;
}
2.3、链式队列
1 | //结点定义 |
初始化
1
2
3
4void InitQueue(LinkQueue &Q){
Q.front=Q.rear=(LinkNode*)malloc(sizeof(LinkNode));//建立头结点
Q.front->next=NULL;
}判队空
1
2
3
4bool isEmpty(LinQueue Q){
if(Q,front==Q.rear)return true;
else return false;
}入队
1
2
3
4
5
6
7void EnQueue(LinkQueue &Q,ElemType x){
s=(LinkNode *)malloc(sizeof(LinkNode));
s->data=x;
s->next=NULL;
Q.rear->next=s;//将新节点插入到队尾
Q.rear=s;//队尾指针移动到新的结点s
}出队
1
2
3
4
5
6
7
8
9bool DeQueue(LinkQueue &Q,ElemType &x){
if(Q.front==Q.rear)return false;//空队
p=Q.front->next;//因为有头结点,所以对头应该是next,然后给p临时变量
x=p->data;
Q.front->next=p->next;//然后让头结点,指向头结点的下一个结点。
if(Q.rear==p)Q.rear=Q.front;//如果队列中只有一个结点,则队头等于队尾,为空了。
free(p);
return true;
}
三、二叉树
1 | //二叉树的链式存储结构 |
四、图
连通:在无向图中,从顶点v到顶点w有路径存在
连通图:图中任意两个顶点都是连通的。
连通分量:无向图中的极大连通子图,极大也就是要包含所有的边。
极小连通子图:既要保证图连通,也要保证边数最少。
强连通:有向图,顶点v到顶点w,与顶点w到顶点v之间都有路径。,为强连通的。
强连通图:邮箱途中,任意一对顶点都是连通的。
边权:图的每条边标上数值,数值为权值
网:带边权的图为网。
1、图的存储


- 本文作者: Victor Dan
- 本文链接: https://anonymousdq.github.io/victor.github.io/2018/07/01/算法与数据结构/
- 版权声明: 本博客所有文章除特别声明外,均采用 Apache License 2.0 许可协议。转载请注明出处!