多层感知器MultiLayer Perceptron
多层感知器又感知机推广而来,最主要的特点是有多个神经元层,因此也叫深度神经网络(DNN:Deep Neural Networks)。MLP是一种前馈人工神经完了过,它将输入的多个数据集映射到单一的输出数据集上。
MLP可以看作是一个有向图,由多个的节点层组成,每一层都全连接到下一层。除了输入节点,每个节点都是一个带有非线性激活函数的神经元。而反向传播算法(BP:Back Propagation算法)的监督学习方法用来训练MLP。
1 | #author:victor |
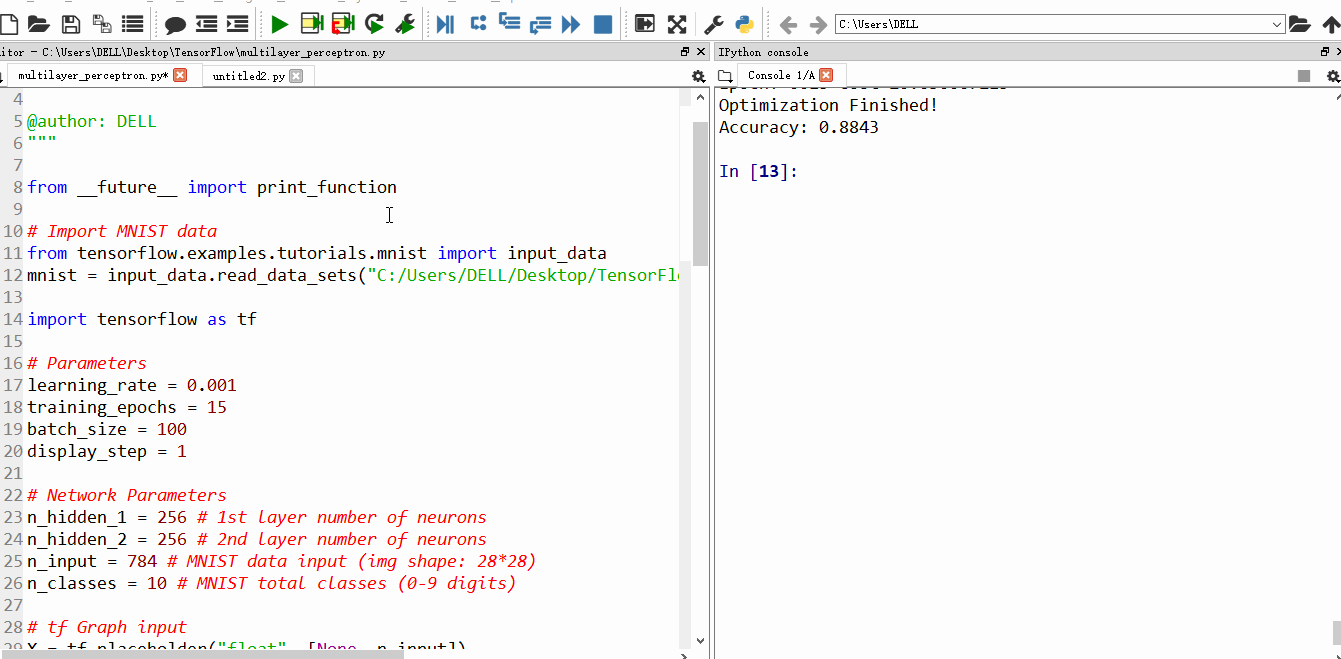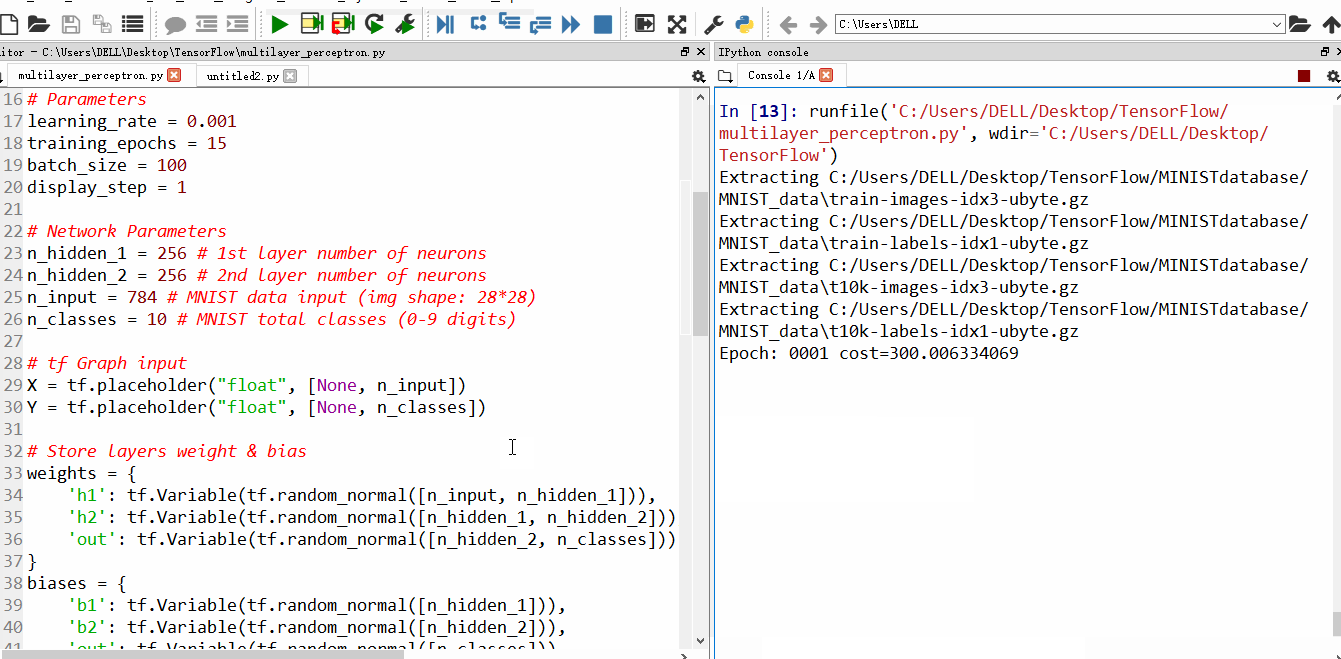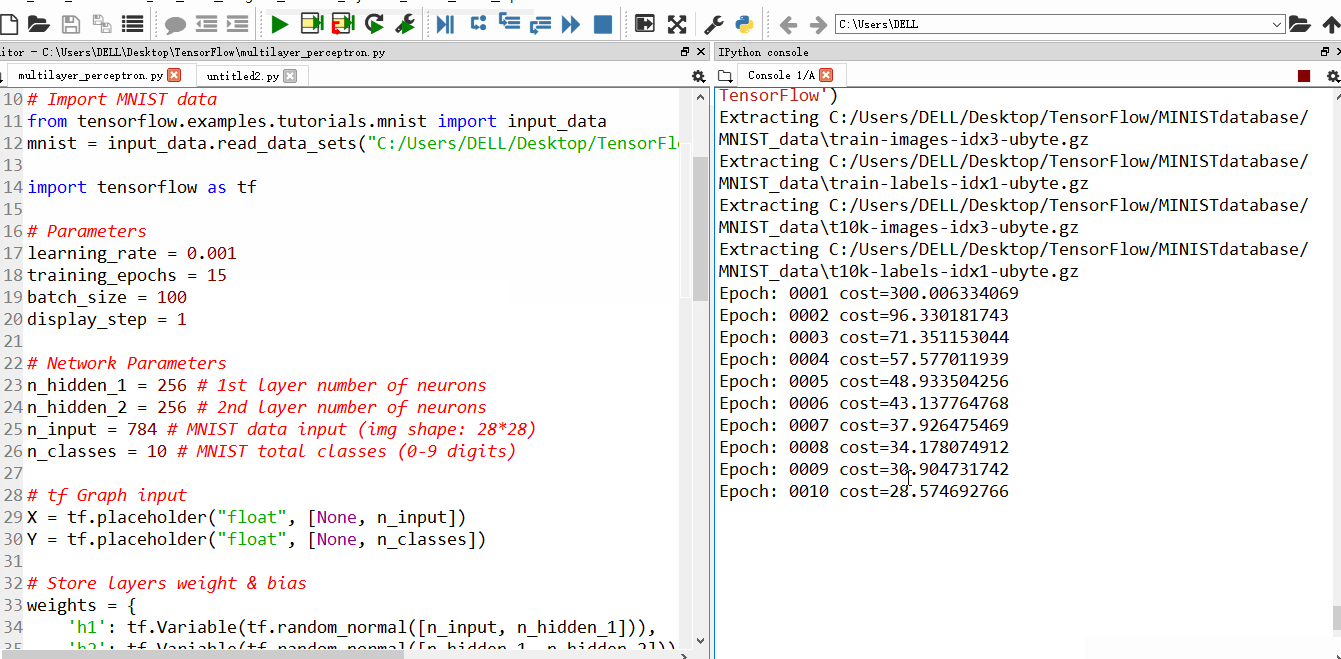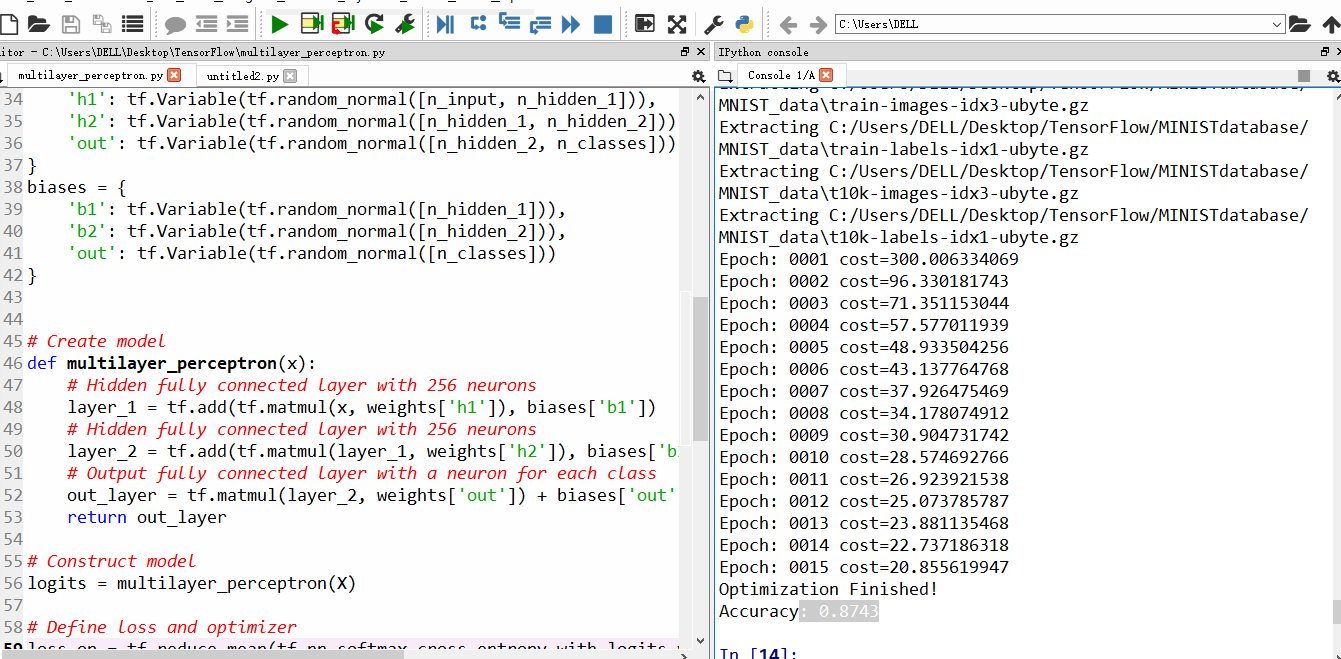
运行结果