RNN入门Demo
耗费了大量时间来讲解RNN和LSTM的原理,并且这一块确实有点难以理解。实践是检验真理的唯一标准,废话不多说,直接上基于TensorFlow平台的RNN加上LSTM优化后的代码和运行效果。
1 |
|
运行效果
- 由于自己是CPU版本的TensorFlow,运行起来比较慢,只能慢慢等待咯
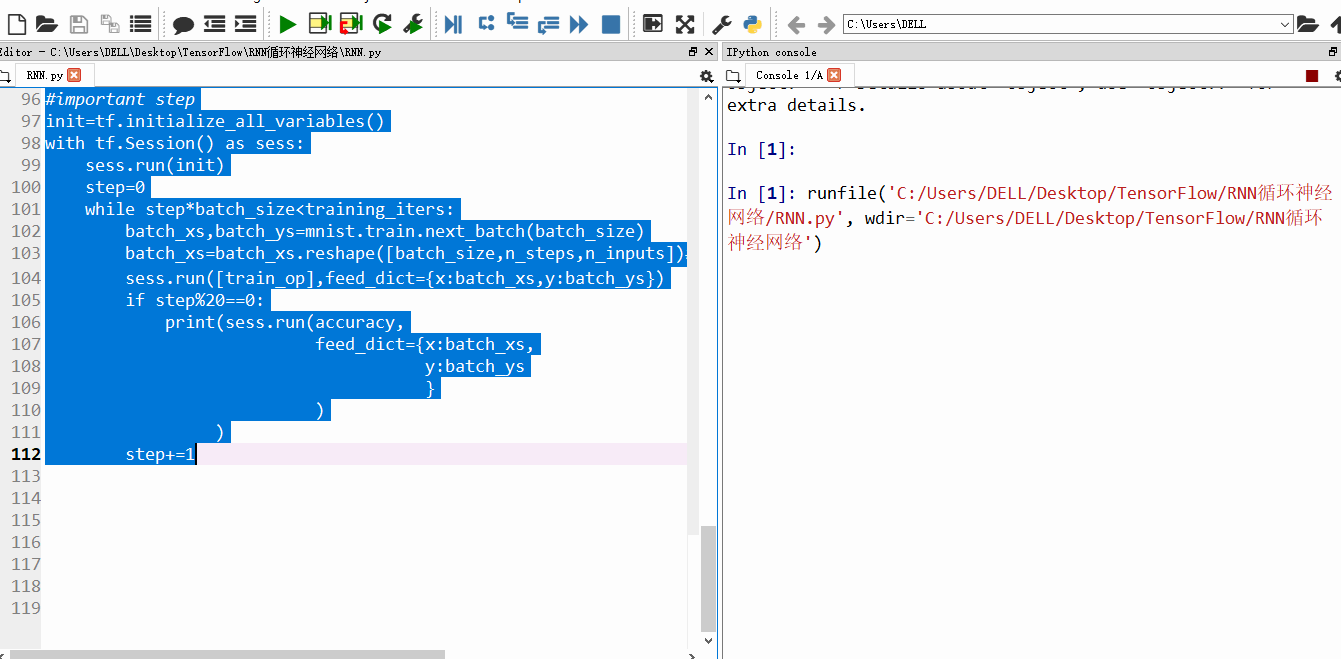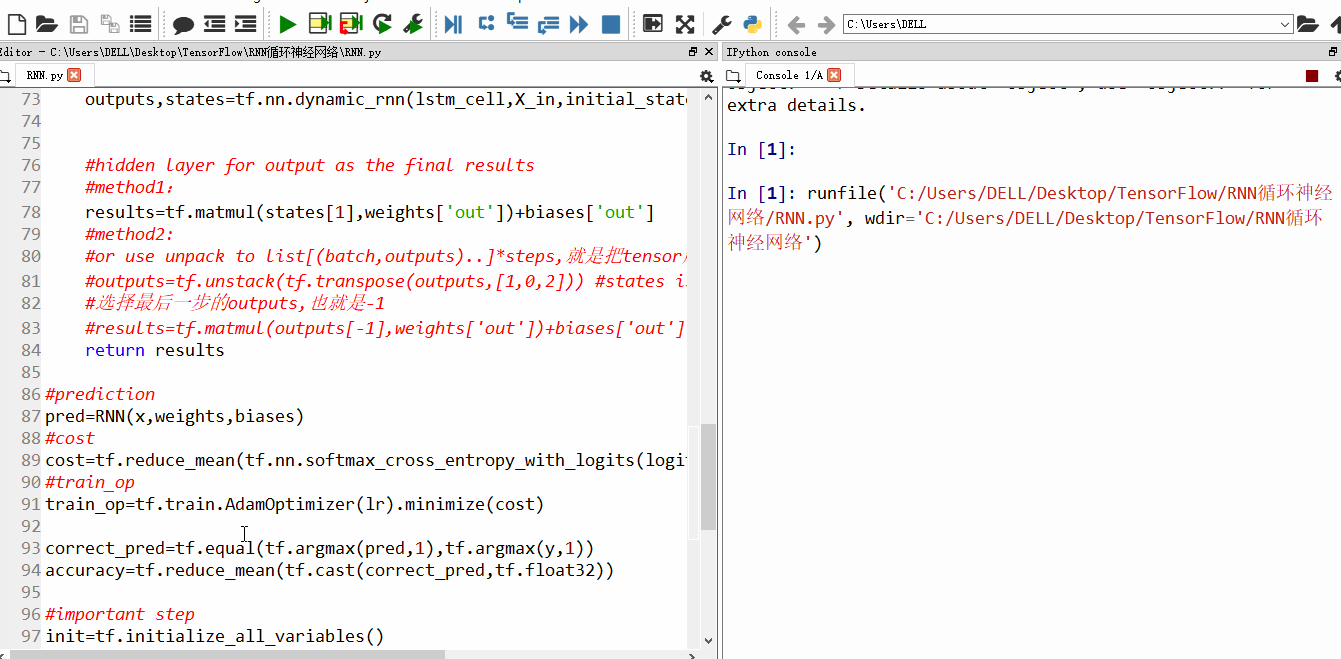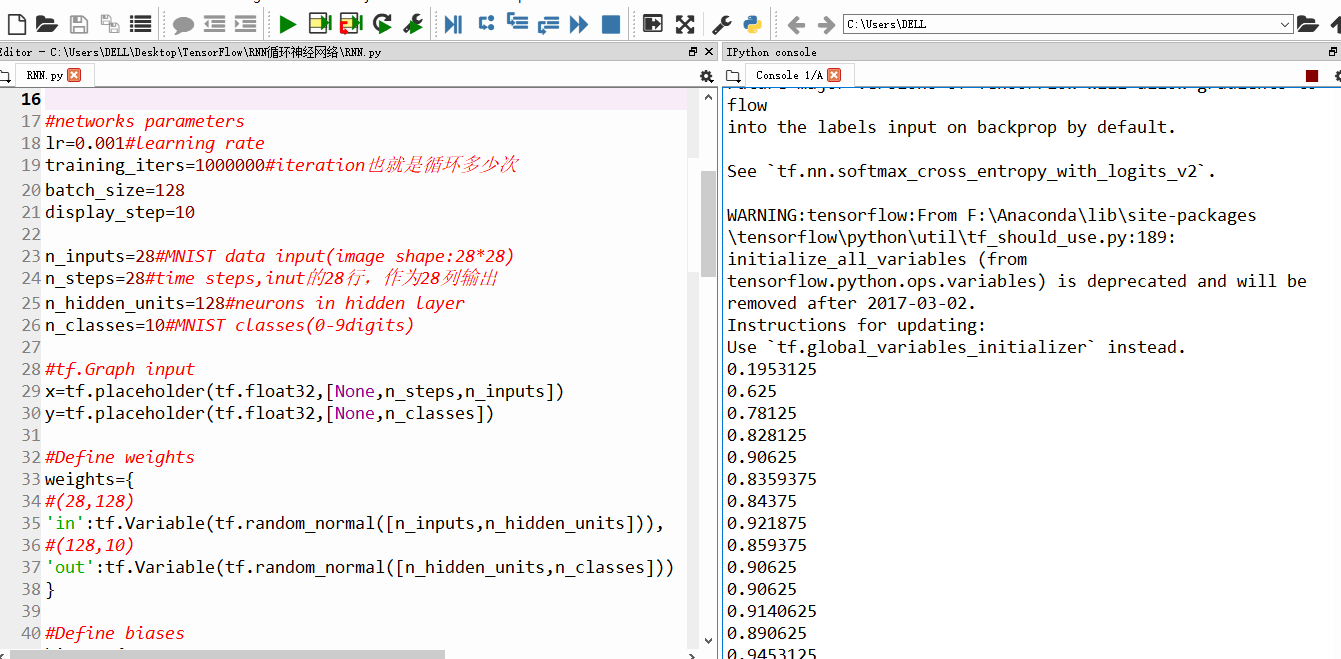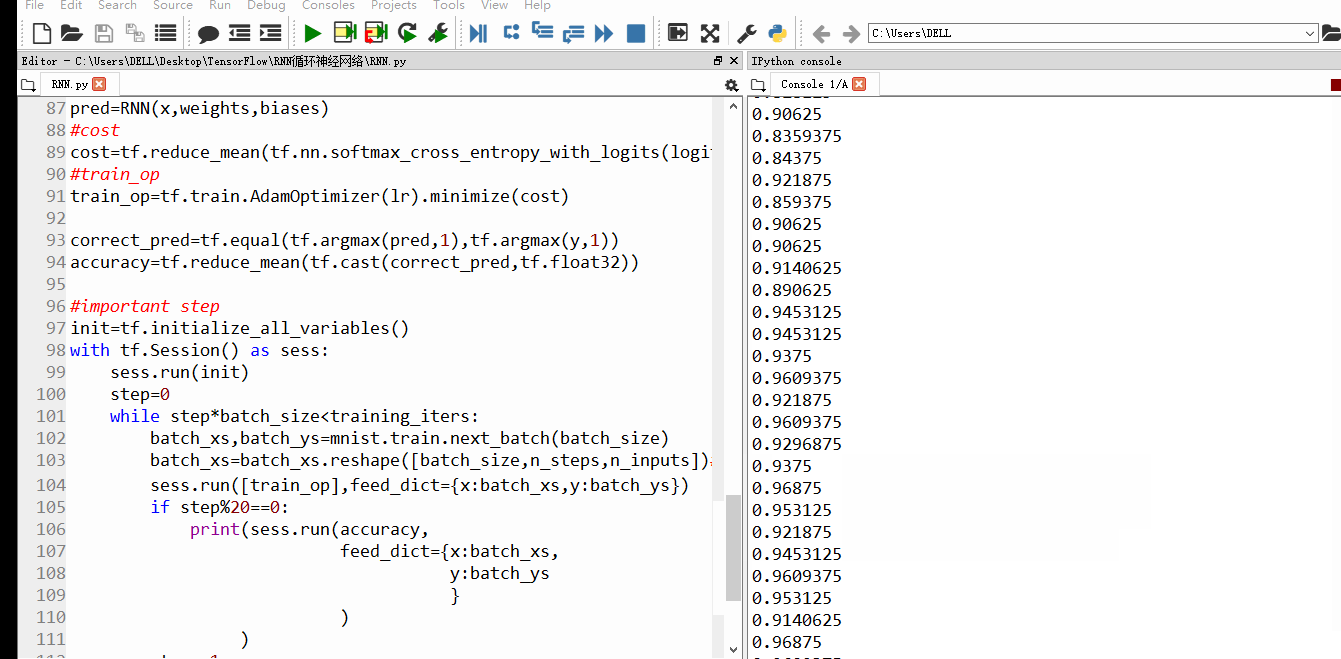
随着训练次数的增加,精确度也渐渐上升
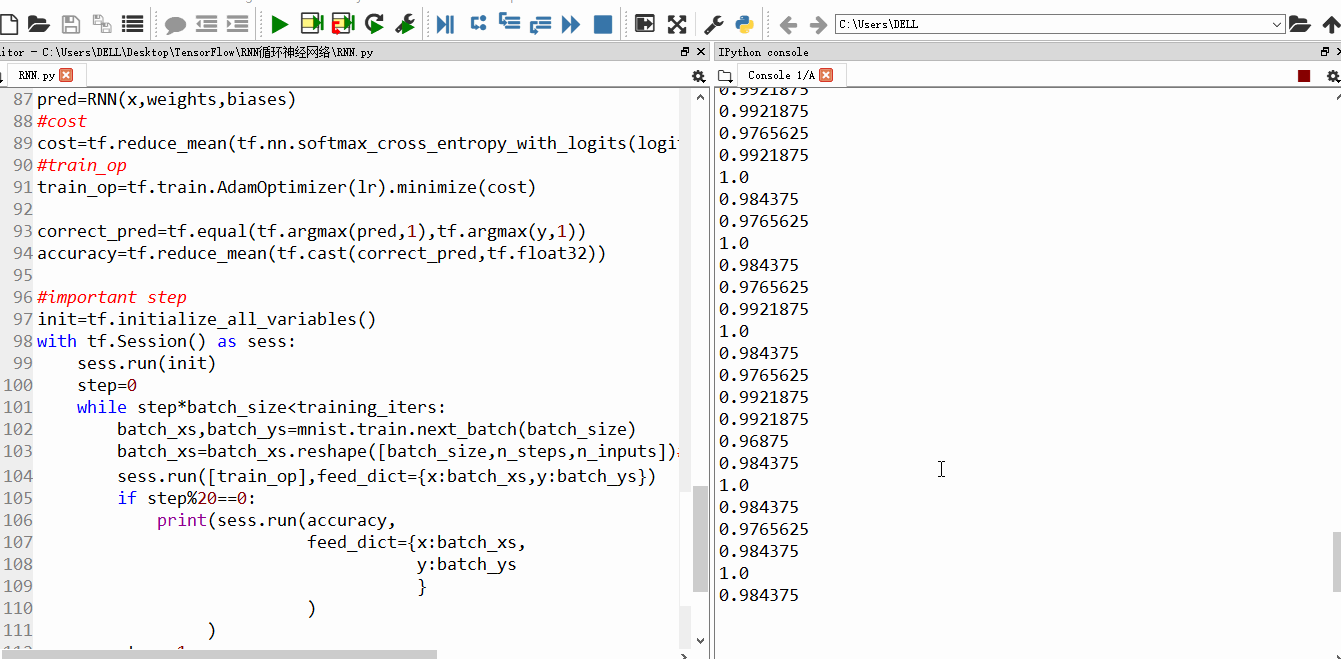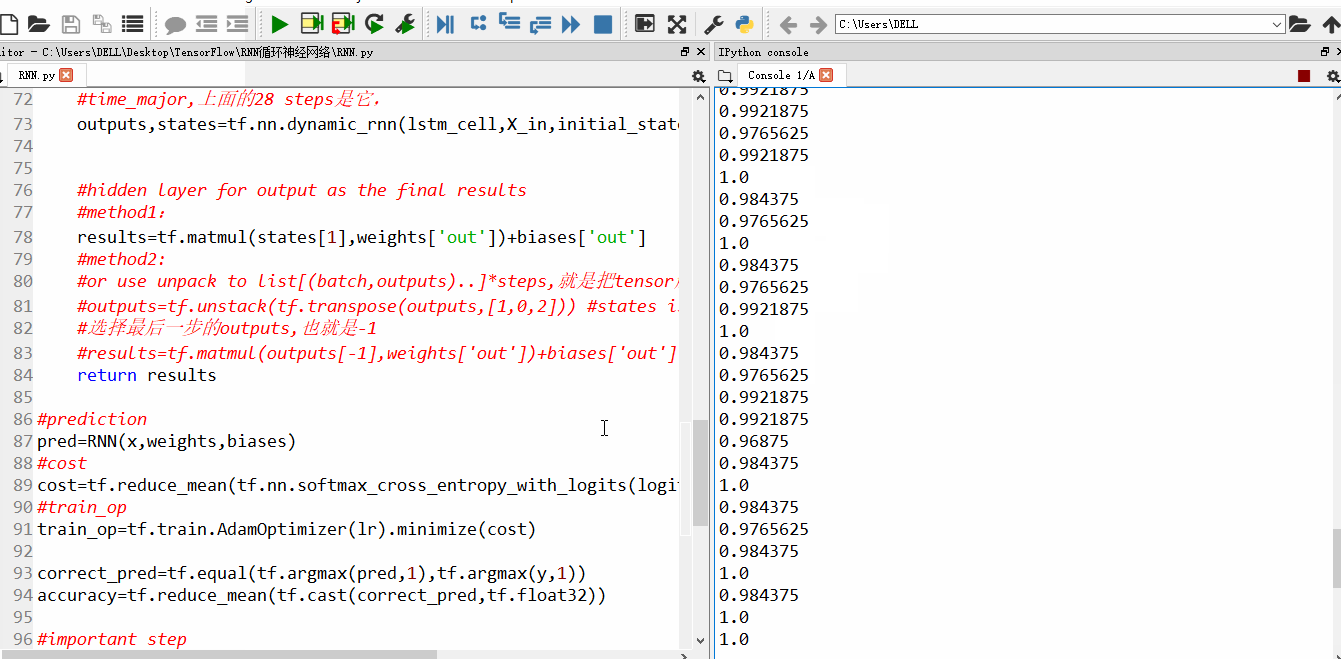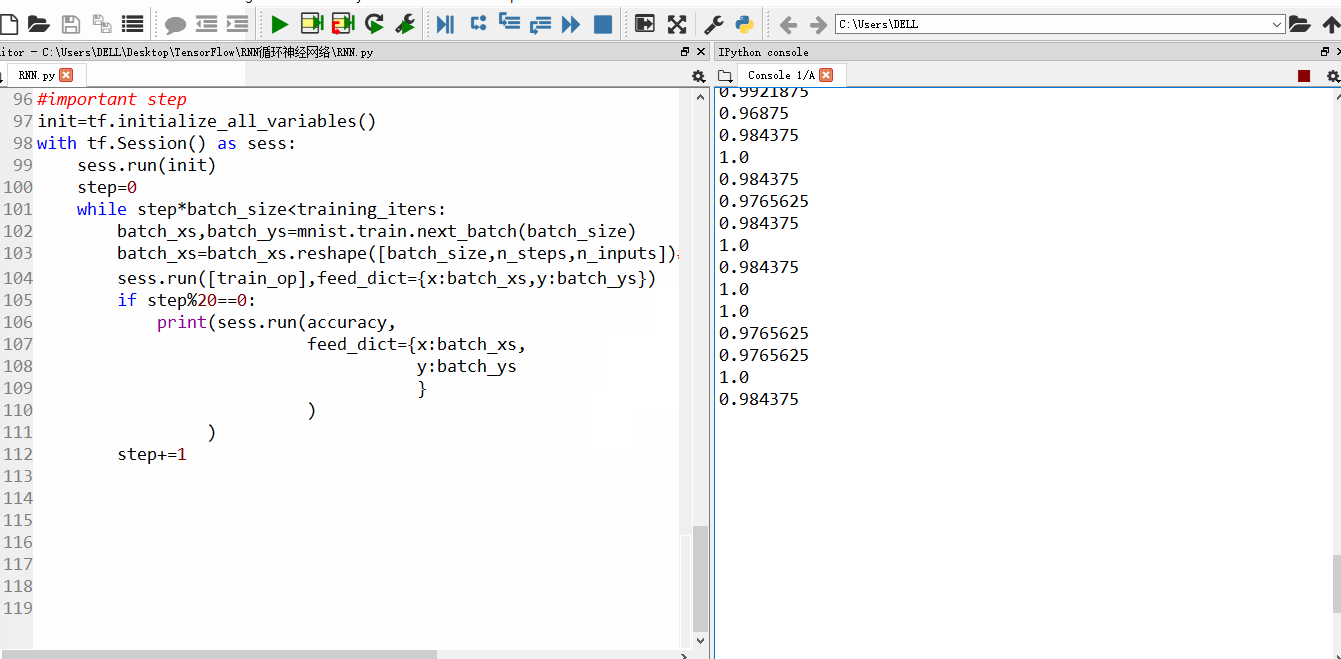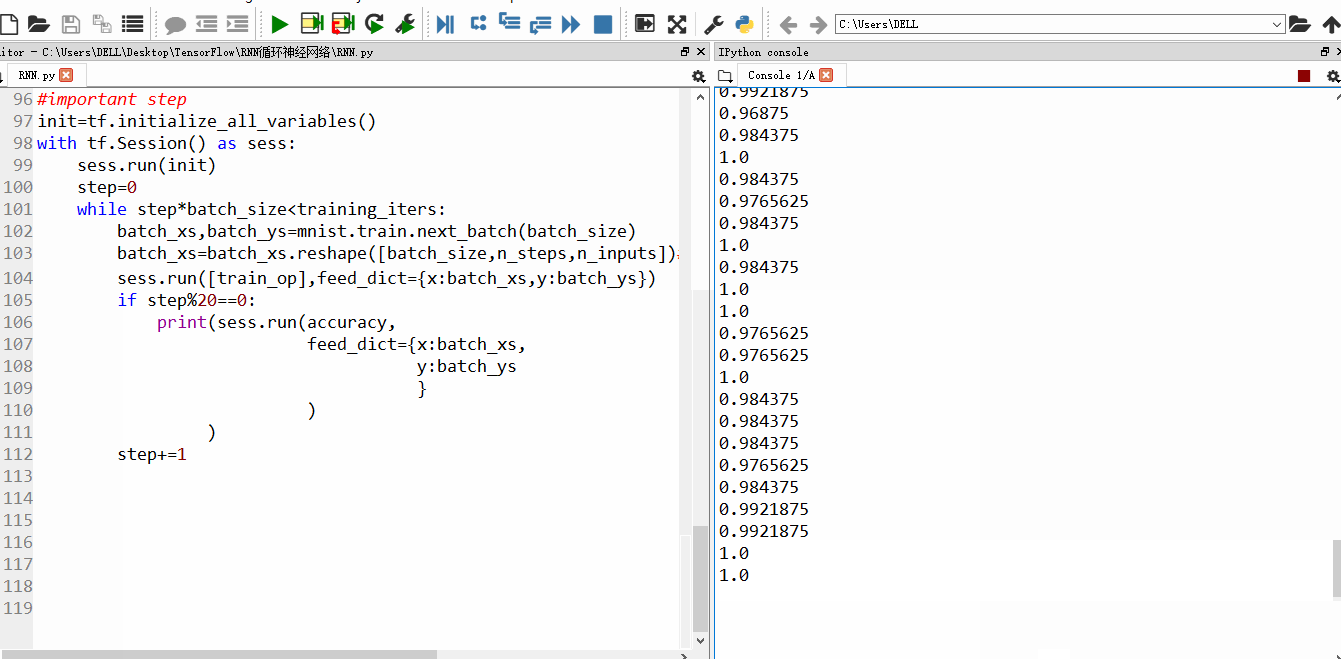
设置的训练100w次,每20步输出一次结果,由于时间太久,我就不一一截图了。训练结束后,精确度99%

耗费了大量时间来讲解RNN和LSTM的原理,并且这一块确实有点难以理解。实践是检验真理的唯一标准,废话不多说,直接上基于TensorFlow平台的RNN加上LSTM优化后的代码和运行效果。
1 |
|
随着训练次数的增加,精确度也渐渐上升
设置的训练100w次,每20步输出一次结果,由于时间太久,我就不一一截图了。训练结束后,精确度99%