Tomcat服务器
就Tomcat服务器优化问题而言,首先Tomcat服务器是一个轻量级的web服务器,Tomcat和微软的IIS服务器一样,具有处理HTML页面的功能,但是Tomcat还是JSP和Servlet的容器。
首先Tomcat服务器优化性能问题可以改善以下内容:
1、增加JVM堆内存的大小
2.解决内存泄漏问题
3、线程池的设置
4、压缩
5、调节数据库的性能
6、Tomcat原生库的使用
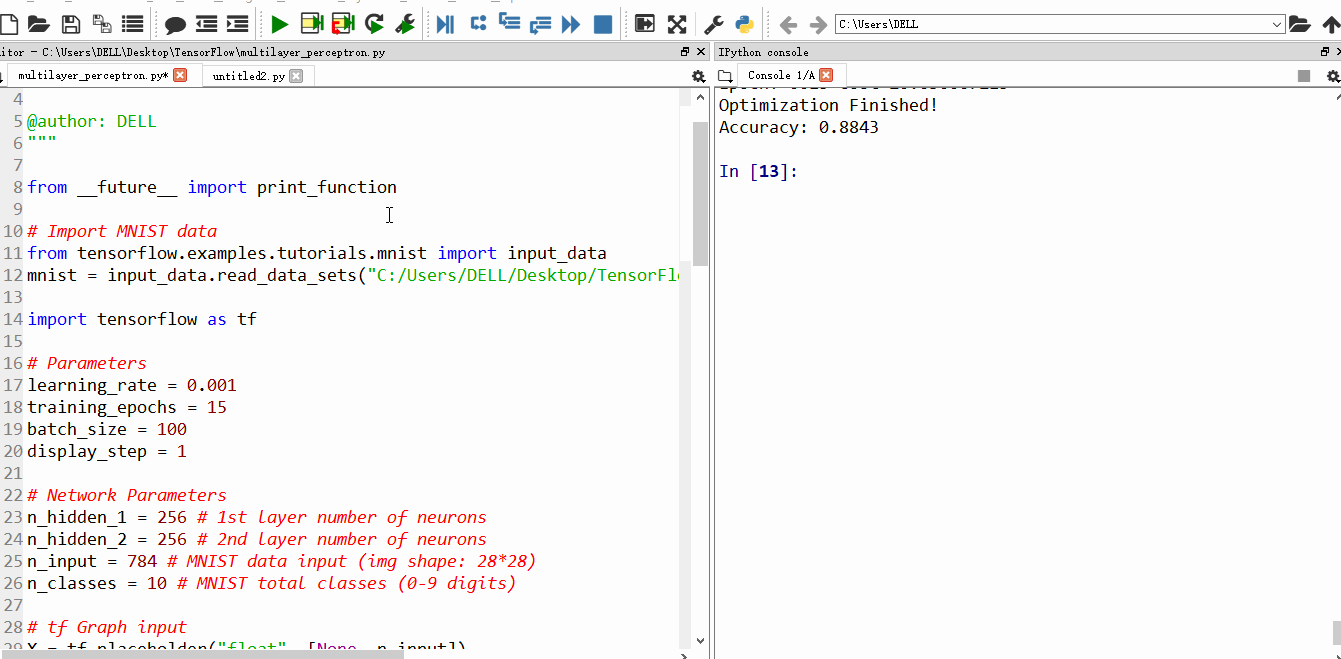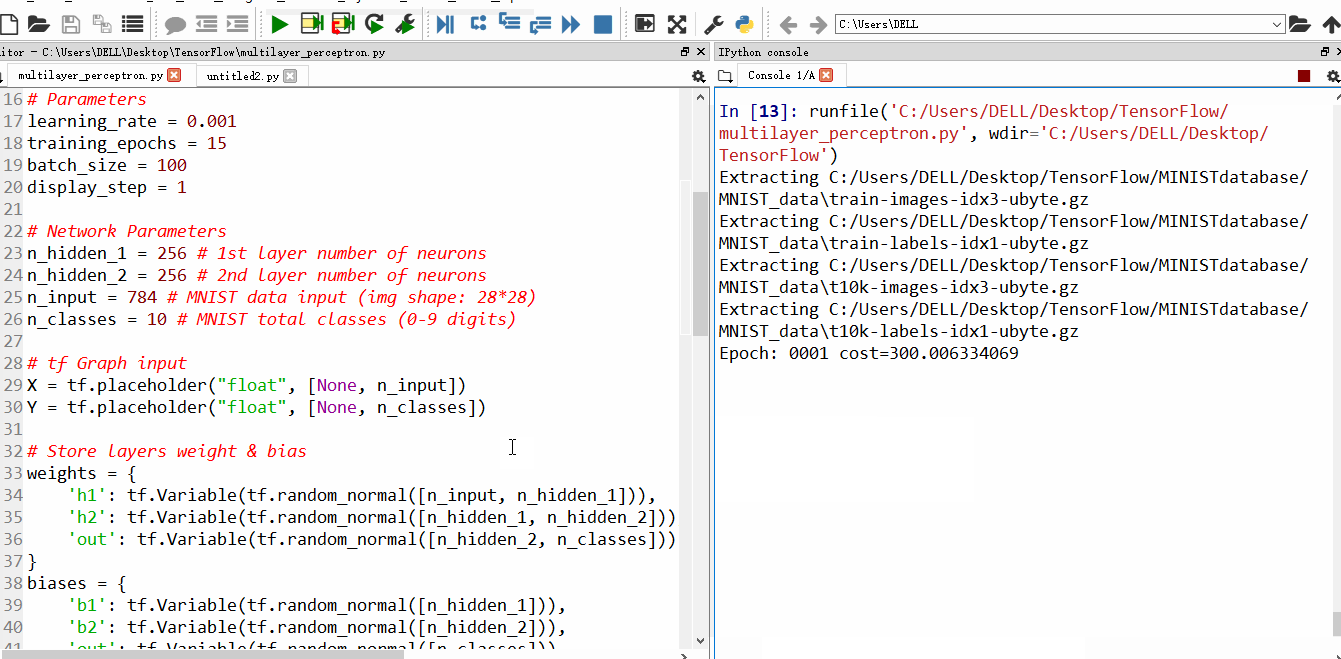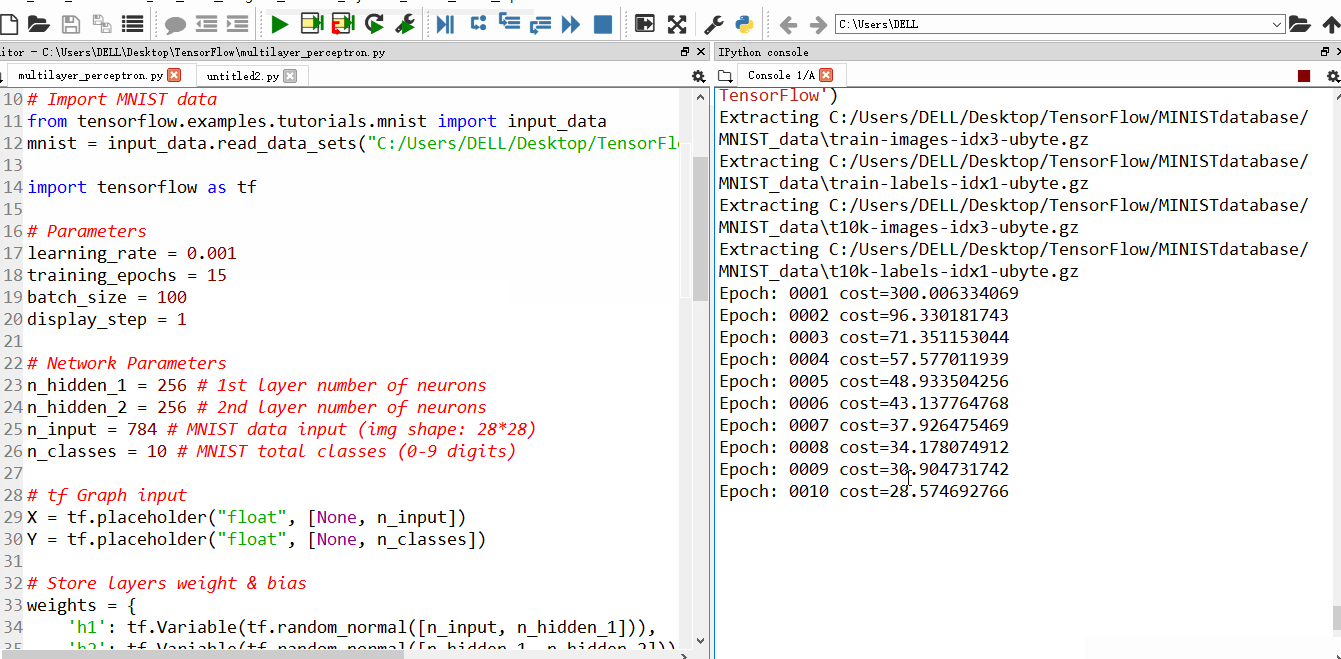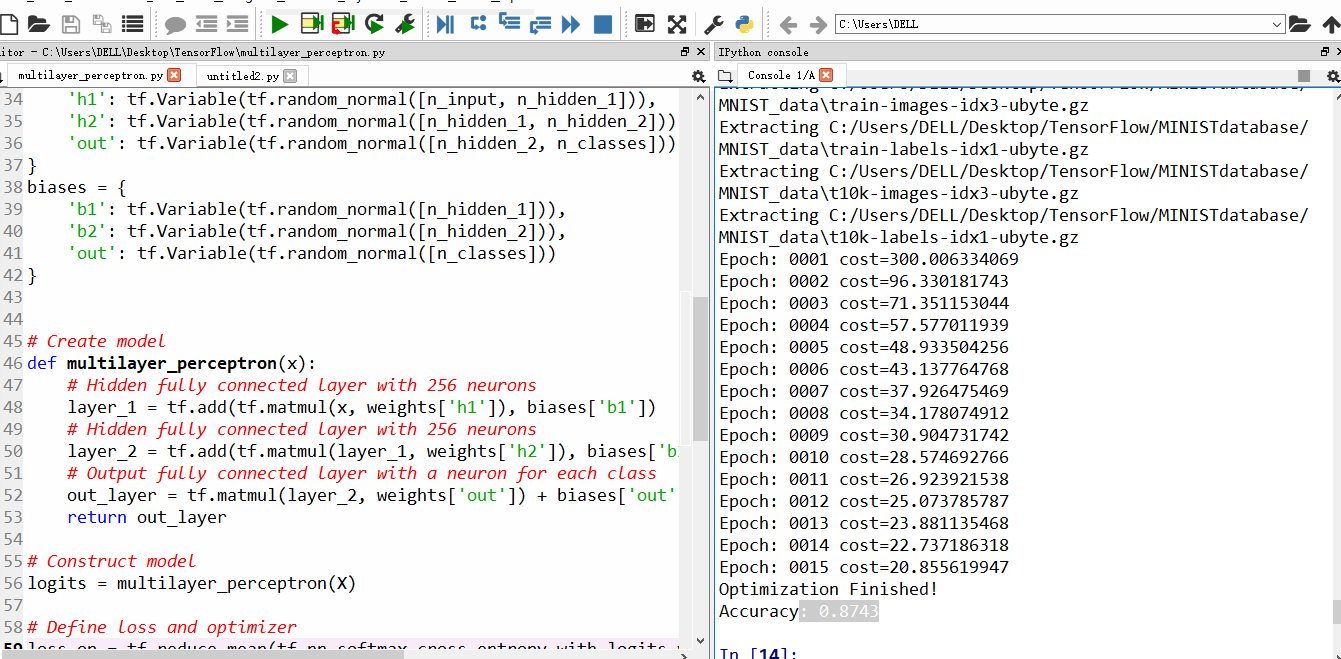
1、先来说说增加JVM内存的问题,当内存溢出的时候,原因是Tomcat使用比较少的内存分配了给了进程,可以通过配置Tomcat文件下的catalina.bat文件,增加JVM内存实现。
1 | -Xms:指定的初始化的栈内存 -Xmx:指定最大栈内存 |
进行重启服务器后,更改。
2、JRE内存泄漏
首先Tomcat的最新版本具有较好性能和可扩展性。可以解决这类错误。通常server.xml配置文件中
有配置一个监听器来处理JRE内存泄漏
1 | <Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener"/> |
3、设置线程池
线程池是用来制定web请求的数量。为了获得更好的服务性能,可以通过调整配置文件里的maxThreads属性来设置。设置的数值大小应该根据请求数据的流量大小,设置的数值过于小,没有足够的线程处理请求,请求处于等待状态,只能等处理线程的释放了一个连接才处理。但是如果设置的数值太大,Tomcat启动又要消耗更多时间。
1 | <Connector port="8080" address="localhost" maxThreads="200" |
4、压缩设置
在server.xml配置文件中设置压缩选项。
1 | <Connector port="8080" protocol="HTTP/1.1" |
5、数据库性能的调节
由于要等待数据库执行查询的时候相应,设置数据库连接池的最大空闲数,最大连接数,最大连接等待时间。
6、使用Tomcat原生库
使用Tomcat的原生库的(Apache Portable Runtime,APR)
7、设置浏览器缓存
设置浏览器缓存,可以使得webapps文件夹里的静态内容比如图片,pdf等内容,读取存取速度更快,提高了整体性能。而且HTTPS请求会比HTTP请求慢,如果为了安全性,还是要选择HTTPS